

Next: Conclusion
Up: Knowledge-based Information Agents
Previous: Information Extraction Engine
Our first information agent CASA (Classified
Advertisement Search
Agent) was built in 1997 [3] to search online real estate
advertisements and help
users to find rental property. It successfully searched for information
automatically from multiple
Web sites. It performed better than local search engines based on keyword
matching.
An agent shell was developed based on the generalization of our first
agent. The reusable agent
framework, including the functions for Web accessing, information
extraction and matching, forms
the main part of the agent shell. The knowledge bases are completely
separated from the
framework and only the general knowledge base forms part of the agent
shell. The other knowledge
bases are kept separate from the shell. New information agents can be built
by adding a new
domain knowledge base and site specific knowledge base to the agent shell.
The agent shell was
successfully used to build a car classified advertisement search agent and
a soccer score search
agent [4].
Our experiments on building agents based on the framework show that:
- Our agent shell can be used to build information agents for multiple
domains and multiple
sites. Our agent can be easily adapted or extended by modifying or
extending its knowledge
bases, while most current information agents are tailored to one specific
domain and are
difficult to scale up.
- Our agents built using the agent shell accept user queries written in
restricted natural
languages, since the information extraction engine can extract specific
requirements from the
user query using the same method for extracting structured information from
Web pages. The
interface of our agents can be as simple as that of keyword search engines
with one single text
input field. The interface is easy to generate and easy to use. The
interface does not need to
change for different domains. This differs from current local search
engines, in which different
user interfaces need to be designed for different domains.
- The information agents generated using our agent shell show better
performance than local
search engines based on keyword matching. The reason is that the
information extraction engine
transfers both the query and Web pages into structured data represented as
a set of knowledge
units. The matching is carried out between knowledge units which is more
accurate than keyword
matching.
In order to evaluate the agent's performance on information extraction from
Web pages, we tested
our agent on Web pages downloaded from over 100 Web sites. This paper will
give some results
based on our basic corpus. Our basic corpus was built by down-loading Web
pages from 24 Web
sites, 12 in the real estate advertisement domain and 12 in the car
advertisement domain. Most
of the Web sites are chosen from the top sites indexed by the search engine
LookSmart at
http://www.looksmart.com.
We use two parameters widely used in information extraction, precision and
recall to evaluate
our system. Precision is the percentage of correct responses out of all
responses. Recall is the
percentage of correct responses out of the total of correct answers. For
each page, the
information extraction answer keys are generated by manually correcting the
output of our
system. The performance of our system is evaluated by comparing the output
with the answer keys.
In order to evaluate the performance of different steps of information
extraction, we calculate
precision and recall for the extraction of knowledge units, knowledge unit
groups, and concepts.
- knowledge unit. Each knowledge unit is correct if its name and value
are the same as that
of the manually generated answers. The precision and recall of knowledge
units indicate the
ability of extracting individual knowledge units from Web pages.
- knowledge unit groups. We define a knowledge unit group as being
correct when the correct
knowledge units have been put in the right concept (group), ignoring false
positive or false
negative knowledge units. The precision and recall of knowledge unit groups
indicate the ability
of grouping knowledge units into concepts.
- Concept. A concept is considered correct when its all knowledge units
at the lower levels
are correct, that is, the concept is perfect, all of its knowledge units
are extracted and all
extracted knowledge units are correct. The precision and recall of concepts
indicate the ability
of extracting a ``perfect concept''.
The results are given in Table  . The results show
that our agent
performs well on multiple Web sites, including Web sites with flexible data
formats such as data
presented as free text in paragraphs.
. The results show
that our agent
performs well on multiple Web sites, including Web sites with flexible data
formats such as data
presented as free text in paragraphs.
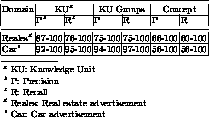
Table: Information Extraction Results
Next: Conclusion
Up: Knowledge-based Information Agents
Previous: Information Extraction Engine
Xiaoying Gao
Tue Dec 11 16:30:56 NZDT 2001