

Next: Experimental Results
Up: Knowledge-based Information Agents
Previous: Three Knowledge Bases
The information extraction engine utilizes the three categories of
knowledge, extracts
information from Web pages and saves the information as structured data.
Figure  shows how it works.
shows how it works.
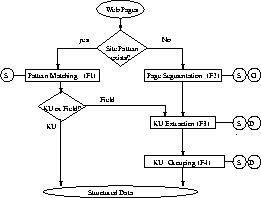
Figure: The Information Extraction Engine
The input to the system is the source file of a Web page with its site name
(the Web site where
the page is downloaded from). The output is a number of concepts, each
concept consists of a
number of knowledge units. The system first checks whether there are site
specific patterns 1)
If yes, then the page is parsed through the pattern matching function.
There are two kinds of
output: a) if the output consists of concepts or knowledge units, they are
directly saved to
structured data. b) if the output consists of fields (each field contains
one or more knowledge
units), then the fields are used as the input to knowledge unit extraction
function, and then
through a knowledge unit grouping function, to be parsed to structured data
and saved. 2) If no,
the page is parsed through three functions: page segmentation, knowledge
unit extraction and
knowledge unit grouping.
The four functions and the categories of knowledge they use are detailed as
follows:
- Pattern matching (F1): this function utilizes site specific knowledge,
including site specific information extraction patterns for concepts,
patterns for individual
knowledge units and patterns for a group of knowledge units (fields), to
parse a page into
concepts, knowledge units and fields. The concepts and knowledge units are
then saved as
structured data and the fields are passed to the next function.
- Page segmentation (F2): this function uses general knowledge of HTML
tag usage and site
specific knowledge of HTML usage, if available, to parse a page into
``lines'', which can be a
line, a table row or an item of a list. It consists of four main steps: 1)
representing a page
as a character list, 2) rewriting the list using two tokens: tags and text,
3) classifying the
tags into groups according to the page structure they represent including
``word'', ``line'',
``paragraph'', 4) segmenting a page into ``lines''.
- Knowledge unit extraction (F3): this function uses either domain
knowledge of knowledge
unit identification and extraction or site specific information extraction
patterns for
knowledge units, if available, to extract knowledge units from each ``line''.
- Knowledge unit grouping (F4): this function groups knowledge units
into concepts and it
uses two kinds of knowledge
- either general knowledge of HTML usage or
site specific knowledge, if available, of HTML usage AND
- either
domain knowledge of a
concept hierarchy or site specific knowledge, if available, of a concept
hierarchy.
Next: Experimental Results
Up: Knowledge-based Information Agents
Previous: Three Knowledge Bases
Xiaoying Gao
Tue Dec 11 16:30:56 NZDT 2001